Appearance
压缩算法测试
我个人运维了一个文档数据库,后续想要朝着大量数据存储进行重写和发展,因此需要测试一下那种压缩算法比较好。整体环境处于一个写多读少,qps 量不高(<100)的状态
防杠说明,除了 snappy 压缩算法外,其他算法均能在 win11 24h2 下压缩和解压,测试方法也是根据我的生产环境。请不要说别说什么打包只用 zip 了,那也没必要计较算法的压缩率了不是吗
压缩算法就是最大化信息密度,而压缩容器(7z 等格式)则是盛放压缩结果的工具,这两者的关系就像是易拉罐和碳酸饮料的关系。一个容器里可能有多种不同的内容物
无损压缩 -> 可以100%还原
kssssssss...ssssssssss(一万个s)
k10000个s
有损压缩 -> 还原的差不多(视觉领域,图片/视频压缩的原理)
kubernetes
k8s如何测试
在测试内容的选择上,需要选择最具有代表性的几个压缩算法和测试对象。这里我选择了六种最常见的压缩算法和三种常见的压缩场景(网页、文本、图片)进行测试。测试方法是对每一个单独文件进行压缩后统计压缩比和吞吐量,只记录计算时间不记录写入磁盘时间,每个场景的总文件大小都在 6G 以上,测试时长最长 5 分钟
测试平台:R7 7700 + qemu 虚拟机中的 win11 24h2
- HTML:从生产数据库中取出了 10000 个 800KB 左右的 json 文件,其中包含多个 HTML 网页
- 文本:从小说文库中提取了 1434 个小说,大小在 500KB-10MB 中随机分布
- 图片:从 CV 测试记录中抽取了 228 个 BMP 文件(无压缩位图)每个 35.2MB(如果是 webp 等现代化文件,压缩的压缩比为 1)
目前按照常见程度和技术发展趋势选择了多个不同的压缩算法(注意这里的均值指的是文本压缩场景)。显而易见 zstd 和 brotli(网页专用) 等新算法要远超 deflate 和 gzip 等旧算法,lzma(即 .tar.xz / .7z)的用低吞吐量换来最极致的压缩率因此在服务分发场景依然常用(压缩一次,分发百万次,节省宽带费用),而 LZ4 用低压缩率换来了极致的吞吐量尤其是服务需要的解压速度,适合需要低延迟的服务使用。bzip2 用高到难以优化的复杂度换来了令人震惊的压缩效果
注:实际上从曲线来看,大部分情况下同压缩率下 zstd 远快于 lzma,同压缩速度下 zstd 压缩率远高于 lz4。因此 zstd 是当之无愧的压缩之神,满足既要又要的需求
| 算法名 | 对应容器 | 算法 | 介绍 | 均值压缩比 | 均值压缩速度 | 均值解压速度 |
|---|---|---|---|---|---|---|
| deflate | zip,gz | LZ77+霍夫曼 | 最经典的压缩算法 | 1.98 | 48.08 | 338.76 |
| bzip2 | 7z | BWT&MTF+霍夫曼 | 高复杂度、极低速度 | 2.43 | 20.91 | 40.97 |
| lzma | xz | LZ77+范围编码 | 高压缩比,低速度 | 2.56 | 7.24 | 81.26 |
| lz4 | N/A | LZ77 变种 | 吞吐量特化,接近内存瓶颈 | 1.65 | 168.50 | 1765.32 |
| snappy | N/A | LZ77 变种 | google 自用(菜) | 1.39 | 351.09 | 865.9 |
| zstd | zst | LZ77 变种 + FSE/tANS | 高压缩比、高速度、万用 | 2.37 | 63.99 | 708.89 |
| brotli | br | LZ+霍夫曼+上下文 | 网页压缩领域特化 | 2.20 | 78.52 | 383.61 |
代码编写
和 gemini vibe coding 一下,现在开源对话记录了(笑)。我稍微微调了一下代码,后续手动补充了 snappy 和 bzip2 的测试。zstd 的字典模式我也测试了下,发现完全没有变化
txt
你是谁:你现在作为资深Python核心开发者,收了我100美金雇佣编写符合python zen的简洁、高效、可解释的代码
你的任务是什么:撰写一份测试python下不同压缩算法[deflate,gzip,lzma,zstd,brotli,lz4]在不同压缩等级下的压缩吞吐量和压缩率
环境变量:压缩文件存储目录=FILE_PATH;压缩任务最大耗时=MAX_TIME
代码要求如下:
1. 文件位置:压缩文件存储在目录:ENV下面,其中有多个原始文件,需要依次遍历文件并且压缩,不要将原始文件存储到内存中,随用随读。所有文件都已准备好,不需要创建
2. 计时要求:测试要求为高精度的计时,即只计算压缩和解压缩的时间,读取文件不计入时间范围。且每次压缩完文件后都计算累计纯压缩时间是否超过了最大耗时,如果超过则终止
3. 存储要求:全程压缩测试内容不落盘,即读取原始文件进行压缩后的结果不写入磁盘中
4. 测试流程:在读取文件列表后,选择一个压缩算法和压缩等级对所有文件进行测试,直到测试完所有的文件。最后输出不同压缩算法的吞吐量和压缩率对比
5. 期望输出:当切换到一种算法时:输出当前算法。每一个压缩等级用类似`压缩算法:压缩等级\t压缩率%\t压缩速度\t解压速度`输出结果,只需要输出数据
6. 函数要求:开始测试的入口函数为func(FILE_PATH),负责读取文件列表和调度
开始执行任务吧,我很看好你结果分析
为了方便观看,我将结果绘制成了曲线,按照惯例,越是右上的越好,能包住越多面积的算法越强。注意,为了方便对比,Y 轴的压缩比不是从 0 开始,X 轴的吞吐量是以 2 为底的对数曲线
数据是会说谎的
- 曲线是没有意义的,本质上是离散的点,压缩比快速提升后达到瓶颈,继续提高压缩等级只会降低吞吐量。无法相同吞吐量为基准,而是进行拐点(费效比最优)之间的对比
- 看似高吞吐量的 LZ4 只有 HC 和非 HC 模式区别,非 HC 模式压缩比只有其他算法的一半且 zstd 的吞吐量已经很接近了,HC 模式吞吐量和压缩比双输
- 看似高压缩比的 LZMA 只有在吞吐量被压倒 16MB 以下的时候才能基本超越 ZSTD。而 BZIP2 则用极其低下的压缩和解压速度换来了最高的压缩率(而且不同压缩等级之间的吞吐量相近,可以直接选最高压缩等级)
- zip 和 gzip?一败涂地!现在是看情况选择要不要 ZSTD 的时代
网页
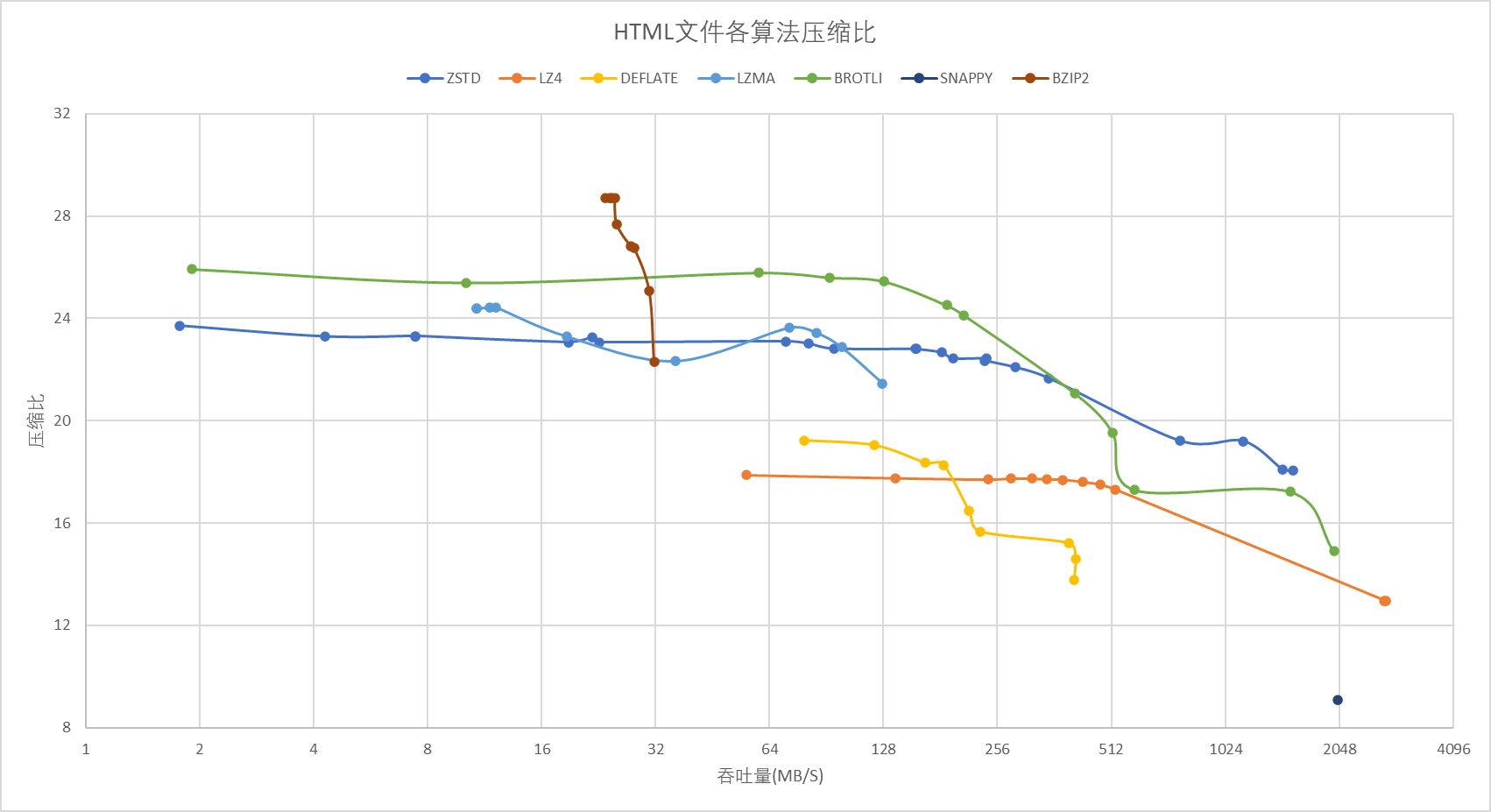
网页其实类似于日志,是高重复的内容,因此在这种场景中各家的压缩比都非常的惊人,甚至没有低于 12 的算法,这与文本和图片场景形成了鲜明的对比。其中专门为网页场景设计的 brotli 简直是一骑绝尘的又快又好,其次则是遥遥领先的 zstd
从曲线上看似 lzma 与 zstd 在高压缩比(8-128M 吞吐量)的时候打的难舍难分,实际上两者的拐点 lzma 的拐点是压缩比为 23.64 时吞吐量为 72.25,而 zstd 的拐点为 22.43,吞吐量高达 239.55,二者的吞吐量根本就不在一个数量级上。lzma 仅在最极限的压缩比(24.44)上取得了优势而代价则是 12.14 的吞吐量,而 bzip2 则是达到了恐怖的 28.72 压缩比但代价是吞吐量 23.56 小于压缩比
当然,考虑到目前压缩的吞吐量甚至不到 qps 级别,差距不大且 python 的哲学就是自带电池最后我应当还是会选择 bzip2
文本
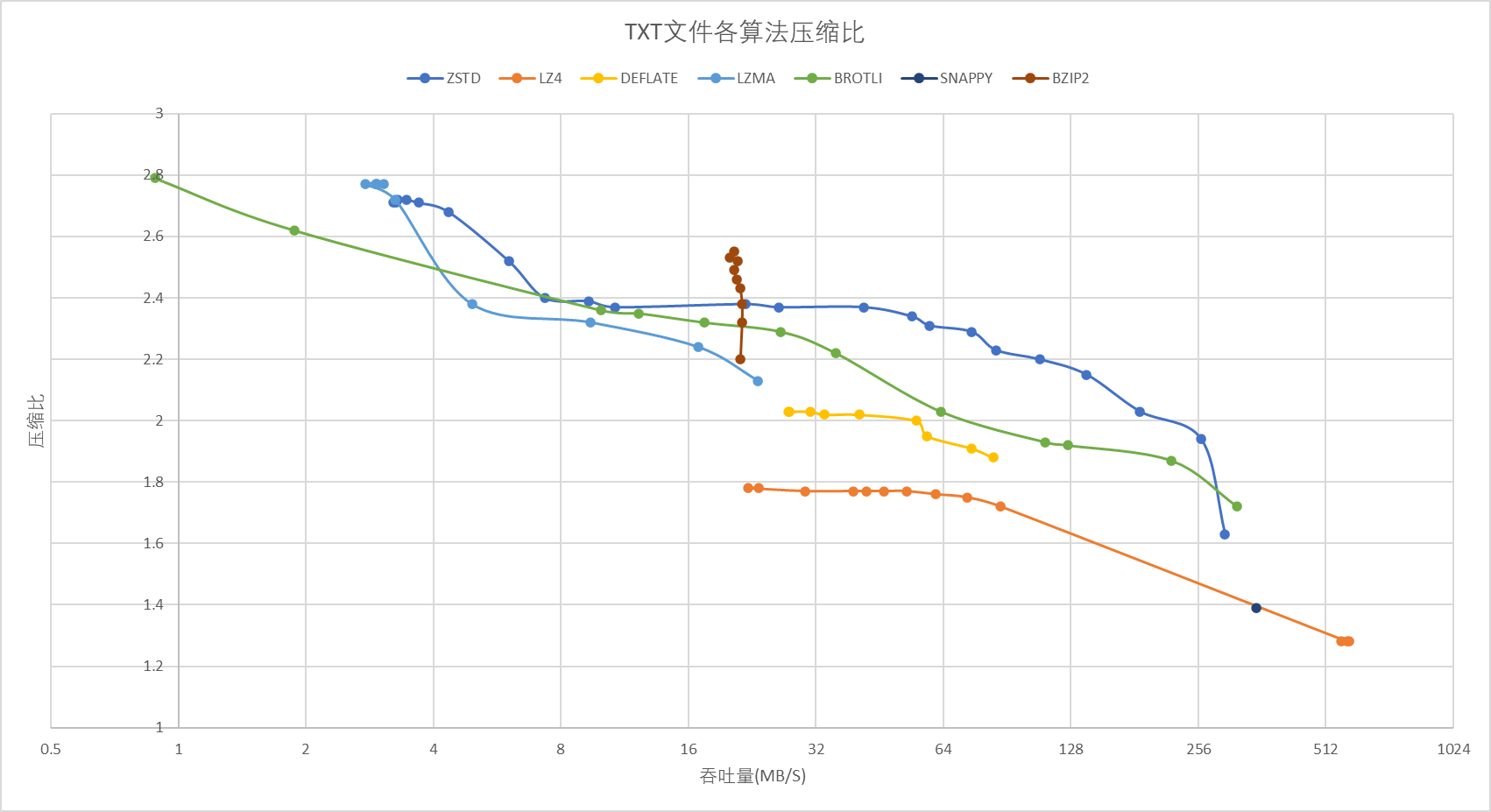
文本我选择的是最常见的场景,找了若干份较大的小说分别进行压缩测试。在这个场景中离开了特化字典适用范围的 brotli 虽然还是基本强于传统压缩算法,但是在真神 zstd 面前还是只能甘拜下风
图片
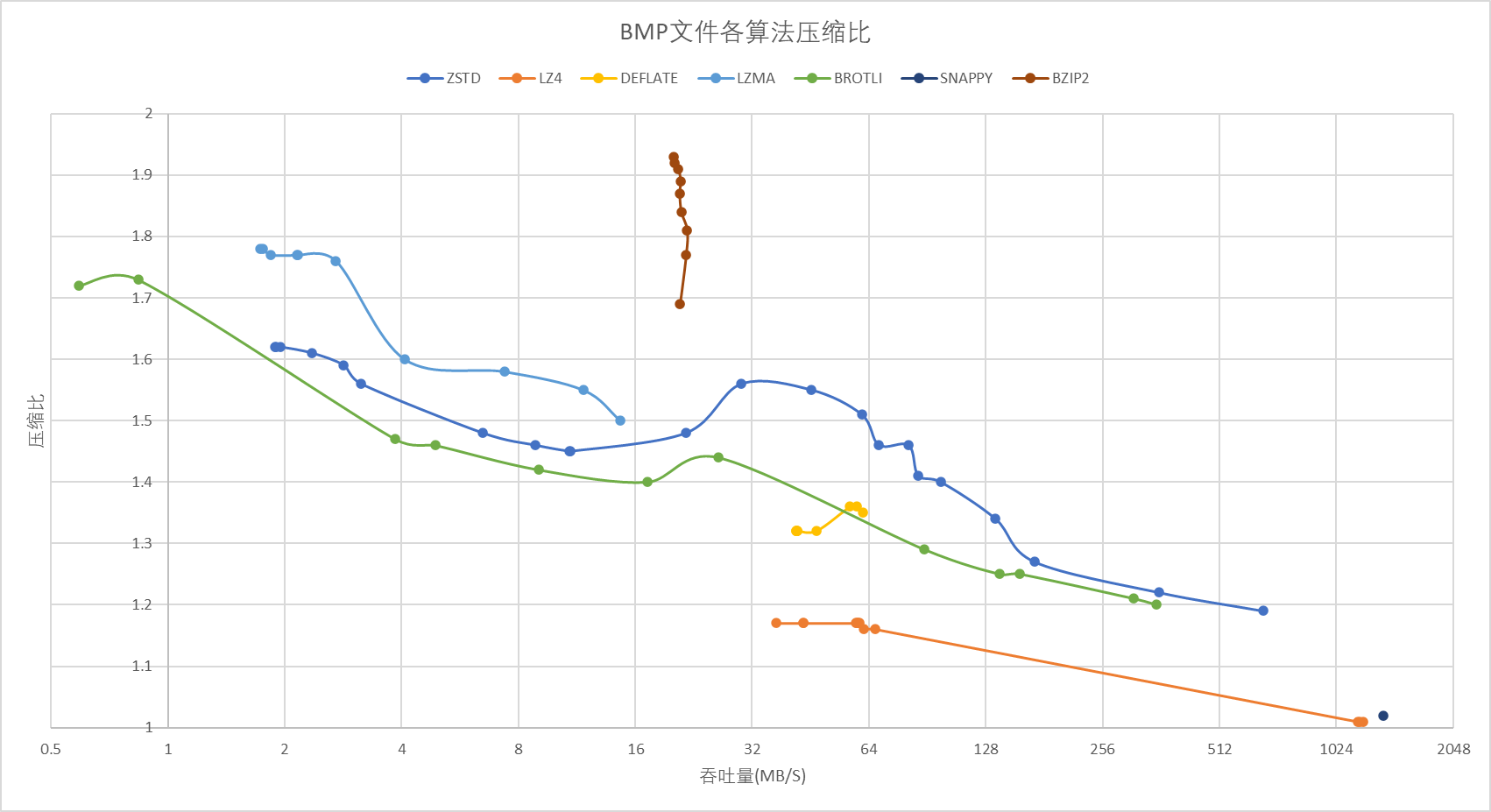
图片走的是视觉无损压缩,传统压缩算法并没有任何实用意义(压 webp 等新算法压缩比只有 1),因此这个部分只是出于兴趣进行测试。以一张信息相对丰富的 bmp(无压缩图片) 为例,原始大小为 35.5MB。LZMA 最高压缩比也就 1.78 也就是 19.94MB,win11 自带的 PNG 压缩后为 15.5MB, 压缩比为 2.29。webp 压缩工具压缩后为 1.33MB,压缩比高达 26.96!
结论
其实从现有的结果上看,结论已经很明确了,新算法其实在大部分阶段上压缩比和吞吐量上全方面碾压了传统的压缩算法(deflate 及 lz4),仅剩少数领域在苦苦支撑(高压缩比还是 lzma 和 bzip2 的天下,要极致吞吐还是 lz4)。除此之外基本上就是 zstd 的天下了
目前 windows 11 24h2 已经支持了 zstd 和 bzip2,所以如果没有特殊要求就直接选择 zstd 压缩即可,需要高压缩比就压缩成 bzip2(注:需要压缩成 tar 格式)